When we think of CSS, we naturally think of styles. Styles to control layout, color and typography. Even styles to progressively enhance our user experience.
Lately, when I’m writing my CSS, I’m thinking about a different kind of style: the style I use to actually write my CSS … more specifically, my selectors.
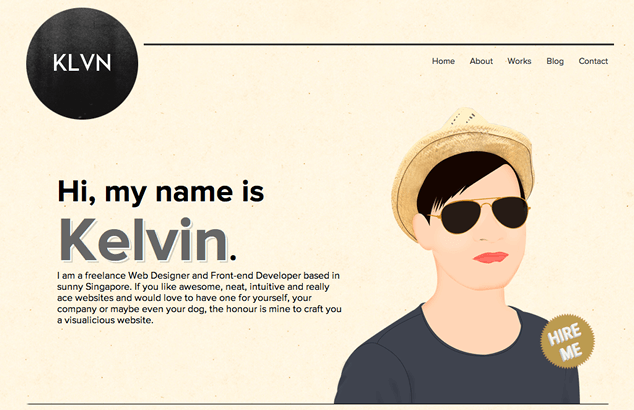
So when I took a look at the reader-submitted portfolio, klvn.org, I was interested in the author’s CSS selector style. Kelvin, like many front-end developers, relies heavily on id selectors in his portfolio:
#introduction {
margin: 0 auto;
width: 960px;
height: 400px;
}As well as class selectors:
.kelvin {
color: #666;
font-size: 100px;
line-height: 100px;
text-shadow: 2px 2px 0 #FFF, 4px 4px 0 #D3CFBC;
}This is the same approach I’ve followed since I wrote my very first selector. Along with your standard type selectors, I’ve almost exclusively used class and id selectors because they are simple to implement.
When I was learning, using classes and ids meant I didn’t have to think about the document tree when styling. But over 13 years of writing CSS, I’ve learned more about class and id selectors so that I can best evaluate whether they are appropriate for a given project, and ensure I’m using them efficiently and appropriately.
class & id Selectors
id selectors can be very useful, especially when you are learning or struggling with the cascade and document tree. However, their high specificity and the fact they aren’t reusable can lead to duplicate CSS. I’ve seen it myself, particularly when working as part of a team on a very large site with thousands of lines of CSS.
classes, too, are useful because they are specific (like ids), but are reusable (unlike ids). This makes them great for newbies unfamiliar with the cascade and, as well as seasoned developers who favor their use.
The reuse factor can lead leaner CSS and easier maintenance, especially for teams. However, without the correct mindset, class selectors can quickly get out of control and bloat your CSS. Consider some of these examples from klvn.org, which are too narrow and limit evolution of a site design:
.bold {
font-weight: bold;
}
.red {
color: red;
}The goal, when using class selectors, is to find a balance so that you can style visual patterns. This is very much like the OOCSS approach, which advocates markup patterns that you can then style with reusable class selectors.
Document Tree Selectors
Along with increasing my understanding of class and id selectors, I’ve also been experimenting with other types of selectors:
- Attribute selectors
- Child selectors
- Sibling selectors
Why? In part, because I understand the document tree more these days and am eager to experiment. Then there’s the fact that more browsers are supporting these types of selectors. But, the true impetus for my changing selector style is that I can do more with more.
What if your site is driven by a legacy system where you can’t access all the markup? Or even a CMS that restricts access to the HTML templates?
These systems are out there. And it isn’t always possible to add classes and ids to the markup. By using attribute, child and sibling selectors, though, I’ve been able to help clients with these types of restricted systems.
Also, thanks to attribute selectors, my markup these days is just a little bit leaner with fewer presentation-only class and id values. Even my CSS is leaner, as I’ve learned to be more judicious with id selectors and more object-oriented with class selectors.
Since expanding my CSS style beyond class and id selectors, my CSS is simply better. I know more options and can, therefore, evaluate the best approach for each project.
In this article, I’ll help you make your CSS better by exploring some of these alternatives to class and id selectors. First, we’ll look at the basic definition of each selector type, as well as a generic example. Then, we’ll see how klvn.org could take advantage of these selectors.
Targeting Elements Based on Attributes
Attribute selectors target an HTML element based on a specific attribute and even a specific attribute value. Consider a link to a PDF:
<a href="/files/schedule.pdf">2012 Workshop Schedule</a>Some designers like to include a little PDF icon alongside the link to give the user a visual cue regarding the file type. But rather than adding a class to this anchor in order to style it, I can write a selector that targets the link purely based on the href attribute and value:
a[href$=".pdf"] {
background: #fff url(/images/pdf.png) no-repeat 0 0;
padding-left: 15px;
/* … */
}And you can be more or less specific with your attribute selectors:
- [attr] selects based only on the existence of a specified attribute
- [attr=”value”] selects based on an exact attribute value
- [attr~=value] selects based on an attribute that contains a series of whitespace-separated words and one of the words is the exact value
- [attr|=value] selects based on an attribute value that starts with the exact value and is appended with a hyphen
- [attr*=value] selects based on an attribute that contains the value
- [attr^=value] selects based on an attribute value that starts with the exact value
- [attr$=value], as in the above example, selects based on an attribute value that ends with the exact value
Browser Support
Attribute selectors enjoy very solid support by all modern browsers, including many mobile browsers:

- Chrome 4+
- Firefox 2+
- Opera 9+
- Safari 3.1+
- Internet Explorer 7+
- Android 2.1+
- iOS Safari 3.2+
- Opera Mini 5+
- Opera Mobile 10+
Do note, though, IE 7 and 8 can be a bit buggy with some of the CSS3 attribute selector variations.
Real World Use
On klvn.org, there are a handful of selectors that the author could easily replace with attribute selectors. On his submit buttons, for example, Kelvin is targeting them with a class selector:
input.button {
display: inline-block;
padding: 4px 6px;
font-size: 12px;
line-height: 1;
color: #3C3C3D;
text-shadow: 1px 1px 0 #FFFFFF;
/* … */
}An alternative method would be to drop the class from the markup and use a selector based on the attributes of the submit input:
input[type="submit"] {
/* … */
}Another selector on klvn.org that could be replaced is that used to target <div id="content" role="main">:
#content {
background: url('images/bg.jpg');
margin: 0 auto;
padding: 0;
width: 960px;
}Since Kelvin is using ARIA Landmark Roles here, he could target the div with:
div[role="main"] {
/* … */
}By targeting the element based on the ARIA role, Kelvin wouldn’t need to add the presentation-only id="content" to his markup.
Targeting Child Elements
Child combinator selectors target HTML elements based on an element’s position in the document tree, specifically an element that is a direct child of another element.
Before we examine how klvn.org could use child selectors, let’s first consider a generic example of a dropdown menu, where the parent level has a different style from the child:
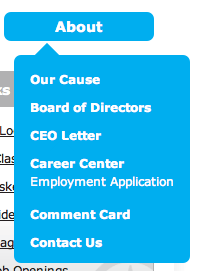
I would mark this up with nested uls:
<ul>
<li><a href="/about/">About
<ul>
<li><a href="/about/our-cause/">Our Cause</a></li>
<li><a href="/about/board-of-directors/">Board of Directors</a></li>
<!-- … -->
</ul>
</li>
</ul>If I used descendent selectors to style the lis, I would need at least two selectors. One to specify styles for the parent level:
ul li {
font-size: 14px;
font-weight: bold;
float: left;
width: 150px;
text-align: center;
margin-left: 12px;
}And one to undo the inherited styles for the child lis:
ul li li {
font-size: 12px;
float: none;
width: auto;
text-align: left;
margin: 0 0 10px 0;
}This would get even uglier and harder to deal with if more nesting was involved for a grandchild level, which I’ve certainly dealt with on large sites with deep navigation.
Wouldn’t it be nicer to just style the parent-level lis and not have to worry about undoing cascaded styles on the children? That’s what the child combinator selector does:
ul > li {
/* … */
}This selector uses a “>” combinator to target only children that are one level down in the document structure. In this example, only the parent lis are targeted. Nested lis won’t inherit any of the styles.
Browser Support
Child combinators have been supported since CSS 2.1:
- Chrome 4+
- Firefox 2+
- Opera 9+
- Safari 3.1+
- Internet Explorer 7+
- Android 2.1+
- iOS Safari 3.2+
- Opera Mini 5+
- Opera Mobile 10+
Real World Use
On klvn.org, the author is actually using a child combinator:
.col1>h1, .col2>h1, .col3>h1 {
font-size: 45px;
margin-top: 0px;
}Interestingly, though, his current content doesn’t need that level of specificity, as there aren’t h1s beyond the direct children:
<div class="col1">
<h1>HTML5</h1>
<p class="colcon">A framework designed to support innovation and foster the full potential the web has to offer.</p>
</div>
<div class="col2">
<h1>CSS3</h1>
<p class="colcon">CSS3 adds a touch of style and effects (animations) that enhances your site without sacrificing the performance.</p>
</div>
<div class="col3">
<h1>Go Mobile!</h1>
<p class="colcon">Have your site optimized for devices running on iOS, Android OS and other mobile devices.</p>
</div>A simple descendant selector for these h1s would work just fine. However, this approach with the child combinator does set the author up for future content scenarios.
Targeting Sibling Elements
Adjacent sibling selectors also target elements based on their position in the document tree. With adjacent siblings selectors, you can target an element that is directly after another element.
I use adjacent sibling selectors alot to fine-tune my typography. For example, I often specify margins for my paragraphs and lists:
p, ul {
margin: 5px 0 10px;
}These values may be perfect when I have two sibling paragraphs:
<p>
<!-- … -->
</p>
<p>
<!-- … -->
</p>But I, personally, like tighter leading between a paragraph and a list:
<p>
<!-- … -->
</p>
<ul>
<!-- ... -->
</ul>Adjacent sibling selectors allow me to target this exact content scenario:
p + ul {
margin-top: -10px;
}The use of the “+” combinator in this example targets only those uls that are the same level in the document tree as the p (siblings) and immediately follows the p in the source markup (adjacent).
Browser Support
Just like child combinators, adjacent sibling selectors have been supported since CSS 2.1:
- Chrome 4+
- Firefox 2+
- Opera 9+
- Safari 3.1+
- Internet Explorer 7+
- Android 2.1+
- iOS Safari 3.2+
- Opera Mini 5+
- Opera Mobile 10+
Real World Use
On klvn.org, there is a section with three columns:
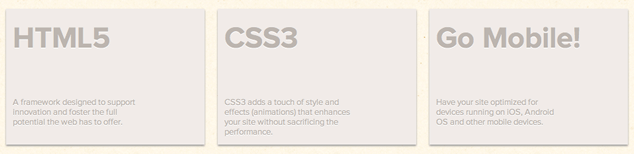
The markup for each column is identical, with the exception of the parent elements’ class values:
<div id="services">
<div class="col1">
<h1>HTML5</h1>
<p class="colcon">A framework designed to support innovation and foster the full potential the web has to offer.</p>
</div>
<div class="col2">
<h1>CSS3</h1>
<p class="colcon">CSS3 adds a touch of style and effects (animations) that enhances your site without sacrificing the performance.</p>
</div>
<div class="col3">
<h1>Go Mobile!</h1>
<p class="colcon">Have your site optimized for devices running on iOS, Android OS and other mobile devices.</p>
</div>
</div>The author is using a class selector to target the ps inside each column:
.colcon {
font-size: 13px;
margin-top: 65px;
width: 70%;
text-shadow: #fff 0px 1px 0px;
}An alternative approach wouldn’t need the class="colcon", but would instead target the p with an adjacent sibling selector:
.col1 h1 + p, .col2 h1 + p, .col3 h1 + p {
/* … */
}With this selectors, only the ps that immediately follow h1s in the columns will be styled. Rather than relying on the specificity of class="colcon", you can rely on the document tree.
As a side note, the .col1, .col2, .col3 naming convention can quickly become a maintenance headache, especially if source order were to change or if new columns were needed. This would be an opportunity to consider a class value that isn’t tied to presentation or source order, such as .column.
It’s About the Project
Now that you know a few of the different ways you can “style” your selectors, how do you decide which approach is best? Ultimately, I believe it comes down to the project you are working on.
- Is it a large site with performance concerns?
- Is the site developed by a team or just one person?
- Will the site be handed off to a different developer or team to maintain?
- Is the site using a CMS that restricts access to source HTML?
For sites with large (even distributed) development teams, class and id selectors can be beneficial from a maintenance standpoint. I’ve inherited CSS that has been a royal mess in terms of organization and commenting, making it difficult to identify the correct selectors to edit. Being able to search by class or id name can make the task significantly easier.
If performance is paramount, the specificity of id selectors can can boost performance over class and other selectors. However, any performance gains are lost the instant you combine it with another selector. This is because browsers read CSS selectors from right to left.
In this example, reading right to left, the browser will first look for the elements identified by the type selectors before moving on to the id selector:
#intro p {
/* … */
}Arguably, there are far more ps on a given web page than #intro, which will increase processing time. That said, differences in performance vary according to the complexity of the CSS and the size of the site.
Similarly, if you consider how browsers parse selectors, child and adjacent sibling combinators are likely going to be less performant than a more specific class or id selector. That said, performance gains of more specific selectors can be minimal, especially when compared to reducing HTTP requests and optimizing images.
Each of the selectors I’ve mentioned in this article come with their own pros and cons that you have to consider against your project. Of course, it should never be an all or nothing proposition. A single CSS file of mine, for example, is a mix of many types of selectors that I choose based on the markup and the project.
Know Your Style, Know Your Options
What I hope you take away from this article is a broader perspective about your CSS. If you know what your options are with selectors, you can better decide what approaches are best for your projects.
It reminds me of the discussion about writing style:
… make sure the style you are using is appropriate to the specific type of writing or publication, understand the reasons behind the style decisions you make, and apply your style choices consistently.
Going the Extra Mile
Curious about your own CSS style? CSS Lint can be a useful tool to get a big picture, as well as recommendations to be more efficient.
Different from a validation tool, CSS Lint essentially checks the style of your CSS against a set of browser performance rules, including:
- Parsing errors
- Empty rules
- Duplicate properties
- Required browser prefixes
- Qualified headings
- Zero value shorthand
All of these can be very useful for identifying problem areas in your CSS and, in turn, improving browser peformance. Keep in mind, though, this is only a tool; the recommendations are not gospel.
In fact, there are a number of CSS Lint recommendations that I disagree with, particularly for my own projects:
- Don’t use IDs in selectors,
- Don’t use adjoining classes,
- Too many floats; use a grid, and
- Too many font size declarations.
This is where your knowledge comes in. Use the tool and then apply your knowledge to decide whether a given recommendation is relevant to your project.
Pitfalls to Avoid
- Don’t add a tag name to your
idselectors.ids should be unique, so qualifying it with a tag (e.g.h2#title) is unnecessary and can slow browser matching. - Avoid complex selectors. Not only can they be a performance hit, but they can make dealing with specificity far more difficult than need be. I try to keep my selectors to a maximum of three.
- If you are having problems with specificity, don’t turn to
!important. This can not only lead to duplicate markup, but becomes a headache for future maintenance.
Things to Do
- Consider other ways to optimize your CSS, including using shorthand where appropriate, organizing and commenting.
- Where you do use
classandidselectors, follow semantic naming conventions. Making yourclassandidnames useful and human-readable will help future maintenance. - Educate yourself, experiment with different selectors, evaluate performance and ease of maintenance, and let your project dictate what it needs.
- If you are using attribute selectors, be aware of unexpected behavior in IE7.
Further Reading
- “Don’t use IDs in CSS selectors?”, Oli.jp, 15 July 2011
- “Landmark roles”, adactio.com, 10 January 2011
- “Simplifying CSS Selectors”, High Performance Web Sites, 18 June 2009
- “Naming and using id’s and classes properly”, mattwilcox.net, 25 July 2011
- “Writing efficient CSS for use in the Mozilla UI”, Mozilla Developer Network, 1 October 2011
- “Style profiler preview”, Opera Dragonfly, 29 November 2011
Do you favor id selectors over classes? How do you evaluate which selectors are best for a given project?